IT之家附上参考地址
- Google DeepMind Researchers Propose GenRM: Training Verifiers with Next-Token Prediction to Leverage the Text Generation Capabilities of LLMs
- Generative Verifiers: Reward Modeling as Next-Token Prediction
IT之家 9 月 3 日消息,谷歌 DeepMind 团队于 8 月 27 日在 arxiv 上发表论文,介绍展示了 GenRM 生成式验证器,创造性提出奖励模型,从而提升生成式 AI 推理能力。
AI 行业内,目前提高大语言模型(LLMs)的主流做法就是 Best-of-N 模式,即由 LLM 生成的 N 个候选解决方案由验证器进行排序,并选出最佳方案。
这种基于 LLM 的验证器通常被训练成判别分类器来为解决方案打分,但它们无法利用预训练 LLMs 的文本生成能力。
DeepMind 团队为了克服这个局限性,尝试使用下一个 token 预测目标来训练验证器,同时进行验证和解决方案生成。
DeepMind 团队这种生成式验证器(GenRM),相比较传统验证器,主要包含以下优点:
在算法和小学数学推理任务中使用基于 Gemma 的验证器时,GenRM 的性能优于判别式验证器和 LLM-as-a-Judge 验证器,在使用 Best-of-N 解决问题的百分比上提高了 16-64%。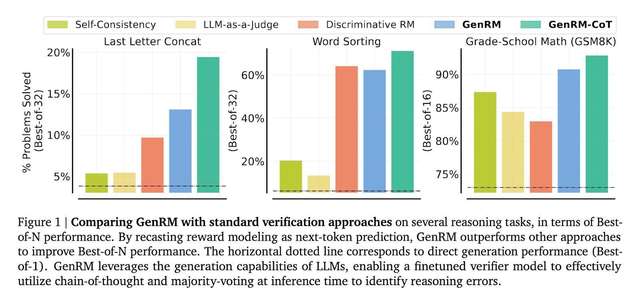

IT之家附上参考地址